
Just recently European Commission has published a comprehensive case study on how Linked Data is transforming eGovernment. One of the three “Further readings” which are mentioned in this publication is “Linked Open Data: The Essentials” in which I wrote an article about “The Power of Linked Data – Understanding World Wide Web Consortium’s (W3C) vision of a new web of data”
Imagine that the web is like a giant global database. You want to build a new application that shows the correspondence among economic growth, renewable energy consumption, mortality rates and public spending for education. You also want to improve user experience with mechanisms like faceted browsing. You can already do all of this today, but you probably won’t.
Today’s measures for integrating information from different sources, otherwise known as mashing data, are often too time-consuming and too costly. Two driving factors can cause this unpleasant situation: First of all, databases are still seen as „silos”, and people often do not want others to touch the database for which they are responsible. This way of thinking is based on some assumptions from the 1970s: that only a handful of experts are able to deal with databases and that only the IT department’s inner circle is able to understand the schema and the meaning of the data. This is obsolete.
In today’s internet age, millions of developers are able to build valuable applications whenever they get interesting data.
Secondly, data is still locked up in certain applications. The technical problem with today’s most common information architecture is that metadata and schema information are not separated well from application logics. Data cannot be re-used as easily as it should be. If someone designs a database, he or she often knows the certain application to be built on top. If we stop emphasising which applications will use our data and focus instead on a meaningful description of the data itself, we will gain more momentum in the long run. At its core, Open Data means that the data is open to any kind of application and this can be achieved if we use open standards like RDF to describe metadata.
Nowadays, the idea of linking web pages by using hyperlinks is obvious, but this was a groundbreaking concept 20 years ago. We are in a similar situation today since many organizations do not understand the idea of publishing data on the web, let alone why data on the web should be linked. The evolution of the web can be seen as follows:
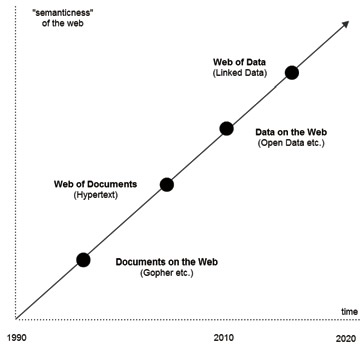
Although the idea of Linked Open Data (LOD) has yet to be recognised as mainstream (like the web we all know today), there are a lot of LOD already available. The so called LOD cloud covers more than an estimated 50 billion facts from many different domains like geography, media, biology, chemistry, economy, energy, etc. The data is of varying quality and most of it can also be re-used for commercial purposes.
All of the different ways to publish information on the web are based on the idea that there is an audience out there that will make use of the published information, even if we are not sure who exactly it is and how they they will use it. Here are some examples:
• Think of a twitter message: not only do you not know all of your followers, but you often don’t even know why they follow you and what they will do with your tweets.
• Think of your blog: it´s like an email to someone you don’t know yet.
• Think of your website: new people can contact you and offer new surprising kinds of information.
• Think of your email-address: you have shared it on the web and receive lots of spam since then.
In some ways, we are all open to the web, but not all of us know how to deal with this rather new way of thinking. Most often the „digital natives“ and „digital immigrants“ who have learned to work and live with the social web have developed the best strategies to make use of this kind of „openness.“ Whereas the idea of Open Data is built on the concept of a social web, the idea of Linked Data is a descendant of the semantic web.
The basic idea of a semantic web is to provide cost-efficient ways to publish information in distributed environments. To reduce costs when it comes to transferring information among systems, standards play the most crucial role. Either the transmitter or the receiver has to convert or map its data into a structure so it can be „understood“ by the receiver. This conversion or mapping must be done on at least three different levels: used syntax, schemas and vocabularies used to deliver meaningful information; it becomes even more time-consuming when information is provided by multiple systems. An ideal scenario would be a fully-harmonised internet where all of those layers are based on exactly one single standard, but the fact is that we face too many standards or „de-facto standards“ today. How can we overcome this chicken-and-egg problem?
There are at least three possible answers:
• Provide valuable, agreed-upon information in a standard, open format.
• Provide mechanisms to link individual schemas and vocabularies in a way so that people can note if their ideas are “similar” and related, even if they are not exactly the same.
• Bring all this information to an environment which can be used by most, if not all of us. For example: don’t let users install proprietary software or lock them in one single social network or web application!
Most systems today deal with huge amounts of information. All information is produced either within the system boundaries (and partly published to other systems) or it is consumed “from outside,” “mashed” and “digested” within the boundaries. Some of the growing complexity has been caused in a natural way due to a higher level of education and the technical improvements made by the ICT sector over the last 30 years.
Simply said, humanity is now able to handle much more information than ever before with probably the lowest
costs ever (think of higher bandwidths and lower costs of data storage). However, most of the complexity we are struggling with is caused above all by structural insufficiencies due to the networked nature of our society.
The specialist nature of many enterprises and experts is not yet mirrored well enough in the way we manage information and communicate. Instead of being findable and linked to other data, much information is still hidden. With its clear focus on high-quality metadata management, Linked Data is key to overcoming this problem. The value of data increases each time it is being re-used and linked to another resource. Re-usage can only be triggered by providing information about the available information. In order to undertake this task in a sustainable manner, information must be recognised as an important resource that should be managed just like any other.
Linked Open Data is already widely available in several industries, including the following three:
• Linked Data in libraries: focusing on library data exchange and the potential for creating globally interlinked library data; exchanging and jointly utilising data with non-library institutions; growing trust in the growing semantic web; and maintaining a global cultural graph of information that is both reliable and persistent.
• Linked Data in biomedicine: establishing a set of principles for ontology/vocabulary development with the goal of creating a suite of orthogonal interoperable reference ontologies in the biomedical domain; tempering the explosive proliferation of data in the biomedical domain; creating a coordinated family of ontologies that are interoperable and logical; and incorporating accurate representations of biological reality.
• Linked government data: re-using public sector information (PSI); improving internal administrative processes by integrating data based on Linked Data; and interlinking government and nongovernment information.
The inherent dynamics of Open Data produced and consumed by the “big three” stakeholder groups – media, industry, and government organizations/NGOs – will move forward the idea, quality and quantity of Linked Data – whether it is open or not:
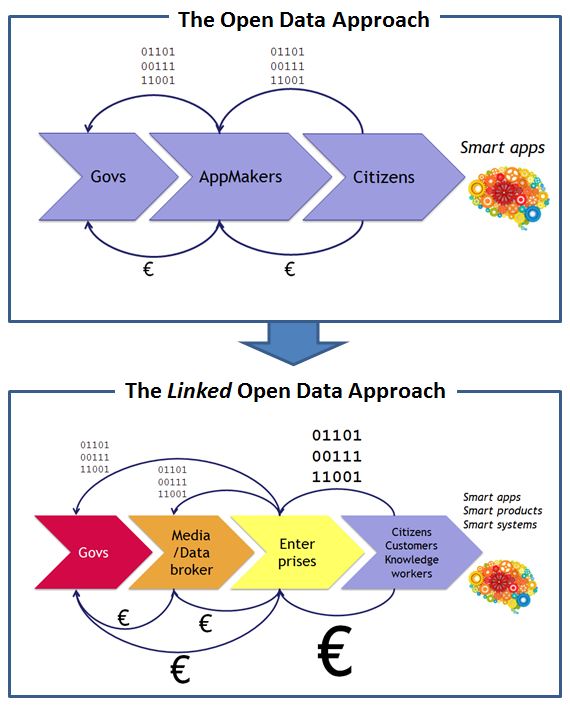
Whereas most of the current momentum can be observed in the government & NGO sectors, more and more media companies are jumping on the bandwagon. Their assumption is that more and more industries will perceive Linked Data as a cost-efficient way to integrate data.
Linking information from different sources is key for further innovation. If data can be placed in a new context, more and more valuable applications – and therefore knowledge – will be generated.

