An active metadata hub – in other words, metadata middleware – uses a data catalog augmented by knowledge graphs and ML to enable the orchestration, interconnection, and enrichment of originally passive metadata. This means not only connecting and capturing metadata from a variety of data sources, but also integrating with other data management tools so that all metadata can be enriched and shared across silos via an active metadata hub that then becomes the authoritative source of metadata across the enterprise.
To make the most of this comprehensive and high-quality metadata treasure trove across a wide range of business processes, an active metadata hub should form the core of an open data ecosystem, be easily accessible via direct integrations and APIs, and thus integrate easily with the existing technology stack.
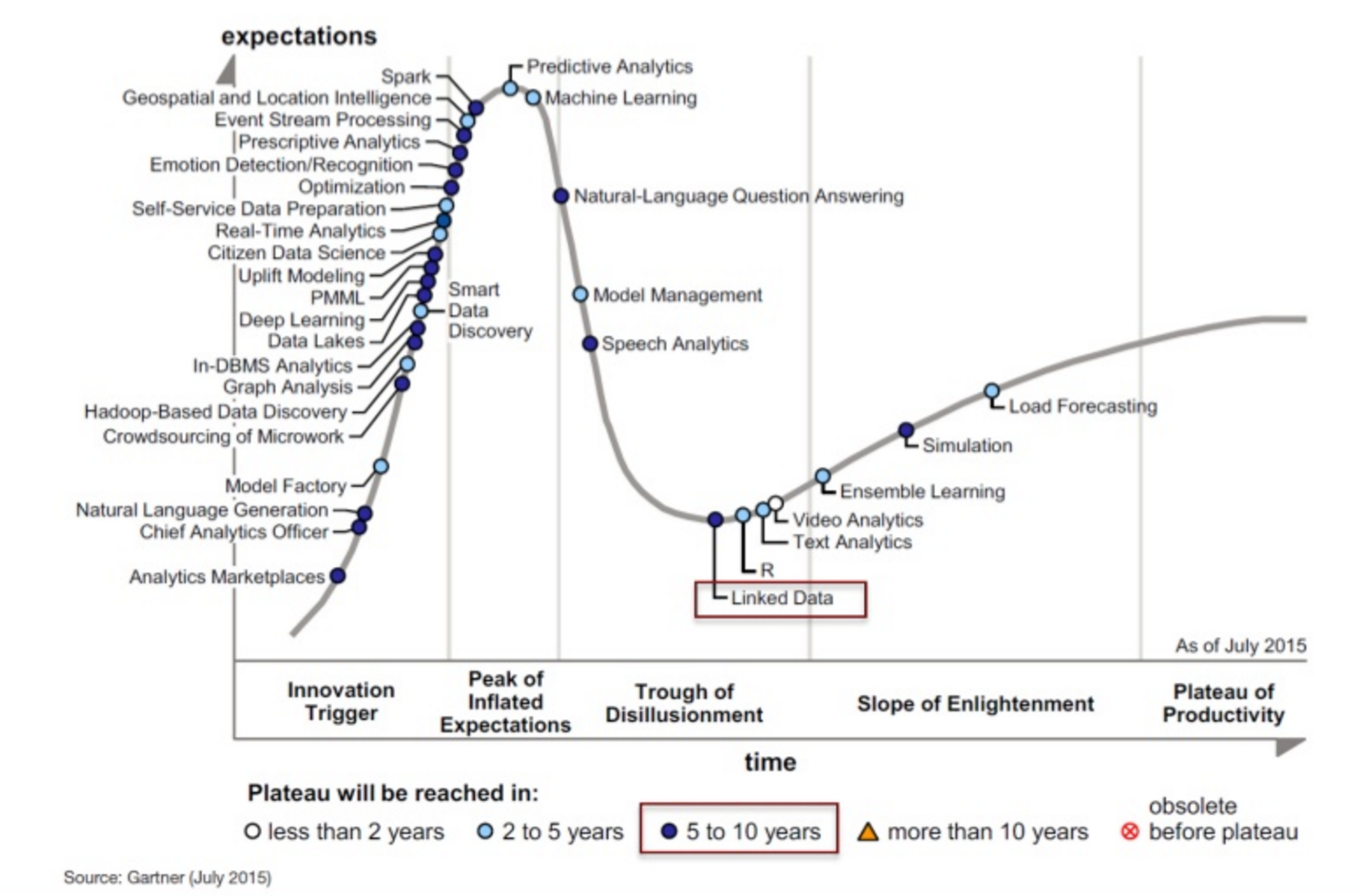
What was conceived in the early 2000s by Tim Berners-Lee at the W3C as the “Semantic Web” for the WWW is now manifesting itself as the Corporate Semantic Web, where active metadata hubs are at the core, in numerous enterprises worldwide.
Gartner refers to “Active Metadata” when, among other things, content analysis tools are used to derive missing metadata and evaluate content change patterns or data profiling tools are used to derive missing metadata and data value change patterns.
The PoolParty Semantic Suite is one of the world’s leading enterprise metadata platforms based on semantic graph principles.
With the end-to-end implementation of a metadata management system based on graph technologies and ML, PoolParty has pursued the vision of ‘Active and Augmented Metadata’ from the very beginning, even though the term was not yet explicitly discussed at the start of development. The vision of self-service data integration is linked to the possibilities of being able to semantically describe metadata with the help of meaningful ontologies and automatically link them with the help of ML procedures, in short: to be able to consistently describe contexts in order to be able to introduce, among other things, intelligent recommender systems or complex classifiers (e.g. for sense extraction from text).
For example, PoolParty can generate active metadata that subsequently triggers activity by combining “passive” metadata with content metadata that can be automatically generated by entity extraction and contextualized or interpreted using a knowledge graph.
In all cases, knowledge graphs play the central role, linking individual metadata, contextualizing them and drawing conclusions from them, which in turn initiate concrete next steps in a workflow.